 As part of Peer Review Week (September 25-29, 2023), it is advantageous for us to explore the changing nature of peer review and the models that have sprung up over the years. For example, as the editor-in-chief for a Taylor & Francis academic journal, College & Undergraduate Libraries, I regularly return manuscripts back to the author as they do not seem to understand that anonymity is required in peer review (the journal uses double-blind peer review), the traditional standard for most academic journals. Double-blind peer review is where the author does not know the peer reviewers (and vice versa) and the peer reviewers do not know each other. This working in isolation allows the reviewer to offer an honest assessment without the taint of bias towards the author or his affiliation.
As part of Peer Review Week (September 25-29, 2023), it is advantageous for us to explore the changing nature of peer review and the models that have sprung up over the years. For example, as the editor-in-chief for a Taylor & Francis academic journal, College & Undergraduate Libraries, I regularly return manuscripts back to the author as they do not seem to understand that anonymity is required in peer review (the journal uses double-blind peer review), the traditional standard for most academic journals. Double-blind peer review is where the author does not know the peer reviewers (and vice versa) and the peer reviewers do not know each other. This working in isolation allows the reviewer to offer an honest assessment without the taint of bias towards the author or his affiliation.
The Peer Review Process
The image from Wiley gives an overview of the peer review process. When the author submits their manuscript, the editor determines whether it is a good fit for the journal. This will include examining the content, relevancy, methodology, and timeliness of the manuscript. If the manuscript is rejected, the editor will explain why. If the editor returns the manuscript and asks for initial revisions, he is interested in sending the manuscript to reviewers. Once the revised manuscript is returned to the editor, he identifies relevant reviewers. The reviewers will usually have four weeks to review the manuscript. The comments can vary in depth and length, depending on the reviewer. In the end, the reviewer decides to accept ‘as is,’ accept with revisions, or reject outright. The editor will make the final call. Most manuscripts are ‘accept with revisions.’ This means the editor asks the author to make certain changes suggested by the reviewer. The purpose of this process is to strengthen the intellectual content of the manuscript.
Types of Peer Review
I mentioned double-blind peer review as the traditional standard of peer review but there are many others. Different peer-review models are given below and some publishers practice multiple models.
- Open Review. Open review makes parts of the peer review process public, either before or after publication. Examples: ScienceOpen and PLOS.
- Journal-independent peer review. This model allows authors to have their manuscripts reviewed before they submit to a specific journal. Example: PeerRef.
- Co-review. Collaborate on reviewing a manuscript with another reviewer. IOP Publishing is currently using this process for their entire journal portfolio.
- AI-assisted review. AI is being slowly rolled in a number of ways (although doubts still remain). (Kousha and Thelwall 2023).
- Post-publication peer review. Once an article is published and available in an open repository, other scholars can come and review it. (Enago Academy).
- Preprint publication. Manuscripts are shared with other scholars before initiating the peer review process. (ArXiv and eLife).
Common Misconceptions regarding Peer Review
In working with authors, I find that many have misconceptions about what constitutes a peer review. Here are some of the common ones.
Misconception: Peer Review is a One-Size-Fits-All Process
As seen above, peer review approaches vary widely, and there’s no one-size-fits-all method. One manuscript may need a different process of evaluation than another. Furthermore, different journals and disciplines can have varying models of peer review to suit their objectives and the nature of the research. For example, you may encounter single-blind review, where the reviewers remain anonymous, or double-blind review, where both reviewers and authors are anonymous to each other. Each review process protects the author and reviewers from potential bias. Howver, in some cases, double-blind review enhances anonymity, but may not be feasible, especially in cases where the author’s identity is obvious. On the flip side, some journals practice open review, where the identities of both reviewers and authors are disclosed, fostering transparency. This approach encourages constructive criticism while holding reviewers and authors accountable.
Misconception: Peer Reviewers are Infallible Experts
Peer reviewers are indeed experts in their fields, but they are not infallible. We all make errors in judgment, oversight, or interpretation, just like any other professionals. Furthermore, biases can inadvertently influence reviewers. Unconscious biases related to gender, ethnicity, or institutional affiliations can impact evaluations. To address this, many journals now focus on diversity in their reviewer pool. For my journal, the publisher has encouraged me to solicit reviewers from countries such as China and India. Editors play a crucial role in ensuring the reliability of peer review. They can act as intermediaries between authors and reviewers, assessing reviews for fairness and rigor. In some cases, they may seek additional opinions or clarification when conflicting reviews arise.
Misconception: Peer Review is a Fast Process
Peer review can be a time-consuming process. From the submission of a manuscript to its final publication, several months may pass, or even longer. This extended timeline can be frustrating for authors eager to share their findings. Factors including journal policies, reviewer availability, rounds of review, editorial process, and scope and complexity of the manuscript can impact the duration of the process. Preprint servers can help authors disseminate their work before the official peer review process and post-publication review can help in discussing research findings.
Misconception: Reviewers Primarily Look for Groundbreaking Findings
At my journal, we look for groundbreaking findings but we also accept manuscripts that contribute to an existent body of knowledge. The peer review process evaluates research based on several criteria, including validity, clarity, and methodology, not just the novelty of findings. Reviewers assess whether the research is conducted rigorously and whether the evidence supports the conclusions. Reviewers will assess the appropriateness of research methods, statistical analyses, and data collection techniques as well.
Misconception: Published Papers are the Gold Standard
While publication in a peer-reviewed journal is a significant achievement, it is not the only standard of research quality. Not all high-quality research gets published. The peer review process is selective, and even well-conducted studies may face rejection for various reasons, including limited journal space, a perception of limited novelty, or specific journal scope. Conversely, not all published work is of high quality. Mistakes, errors, or even ethical lapses can sometimes find their way into published papers. The peer review process helps to identify and mitigate these issues but is not infallible. Last, research impact, citations, and real-world applications also play a role in assessing the quality and influence of a paper. Some groundbreaking research may not gain immediate attention but becomes influential over time.
Enjoy the rest of Peer Review Week!
Further reading
Kousha, K. and Thelwall M. 2023. Artificial intelligence to support publishing and peer review: A summary and review. Learned Publishing. 2023.
Leung T.I., de Azevedo Cardoso T., Mavragani A., Eysenbach G. 2023. Best Practices for Using AI Tools as an Author, Peer Reviewer, or Editor. Journal of Medical Internet Research 2023.
Willis, Michael. 2022. How Can Technology Aid Research Integrity? Wiley blog. November 22.
Wulf, Karin et al. 2023. Ask the Chefs: What is the Single Most Pressing Issue for the Future of Peer Review? Scholarly Kitchen, September 22, 2023.
 Love Data Week 2024, scheduled for February 12-16, presents a unique opportunity for scholars, students, librarians, and data enthusiasts to delve into the multifaceted world of data. This year’s theme, “
Love Data Week 2024, scheduled for February 12-16, presents a unique opportunity for scholars, students, librarians, and data enthusiasts to delve into the multifaceted world of data. This year’s theme, “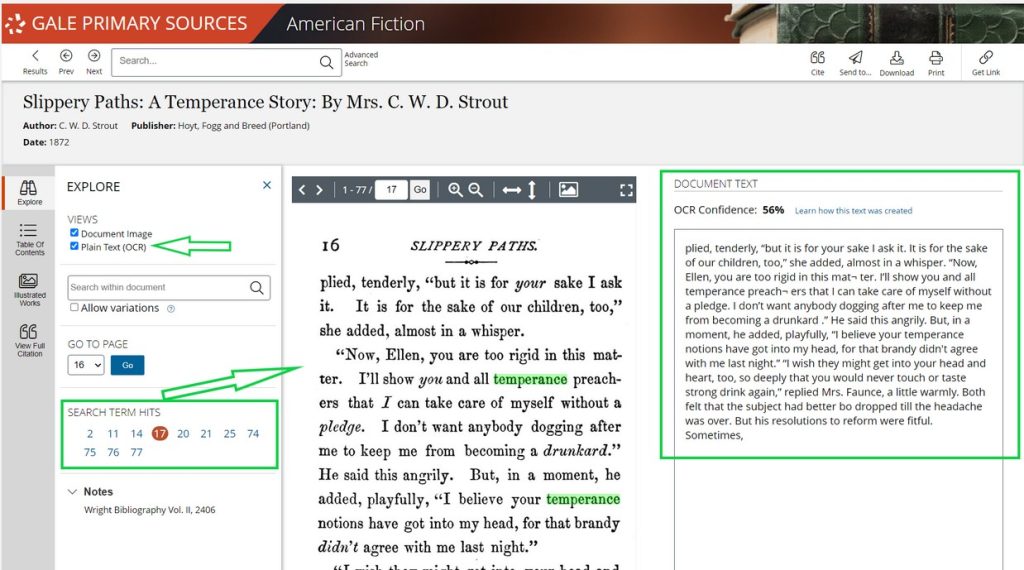
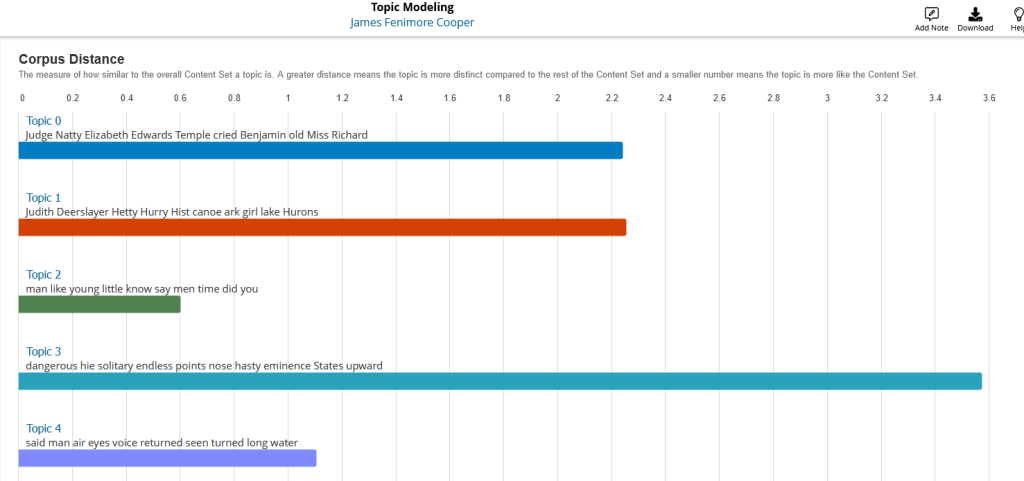






 AFINN Lexicon to assign a “sentiment score” to each document within a researcher’s content set, then provides two interactive visualizations of this data. In this webinar, Senior Digital Humanities Specialist Dr. Sarah Ketchley will show how to run the Sentiment Analysis tool, explain the recent upgrade to this tool, and discuss how Sentiment Analysis can be used in Digital Humanities projects to answer research questions.”
AFINN Lexicon to assign a “sentiment score” to each document within a researcher’s content set, then provides two interactive visualizations of this data. In this webinar, Senior Digital Humanities Specialist Dr. Sarah Ketchley will show how to run the Sentiment Analysis tool, explain the recent upgrade to this tool, and discuss how Sentiment Analysis can be used in Digital Humanities projects to answer research questions.” portal pages focused on works of literature and literary topics, new primary and historical document sets, plus access to an additional 100+ original works of literature. The enhancements are aimed to empower students working with primary sources and to provide instructors with easy-to-find materials that inspire learning.”
portal pages focused on works of literature and literary topics, new primary and historical document sets, plus access to an additional 100+ original works of literature. The enhancements are aimed to empower students working with primary sources and to provide instructors with easy-to-find materials that inspire learning.”